Background
If you own a technical blog or a website you generally need to add code to illustrate your examples. In such cases highlighting the code becomes essential. You would have seen the code syntax highlighting in this blog itself.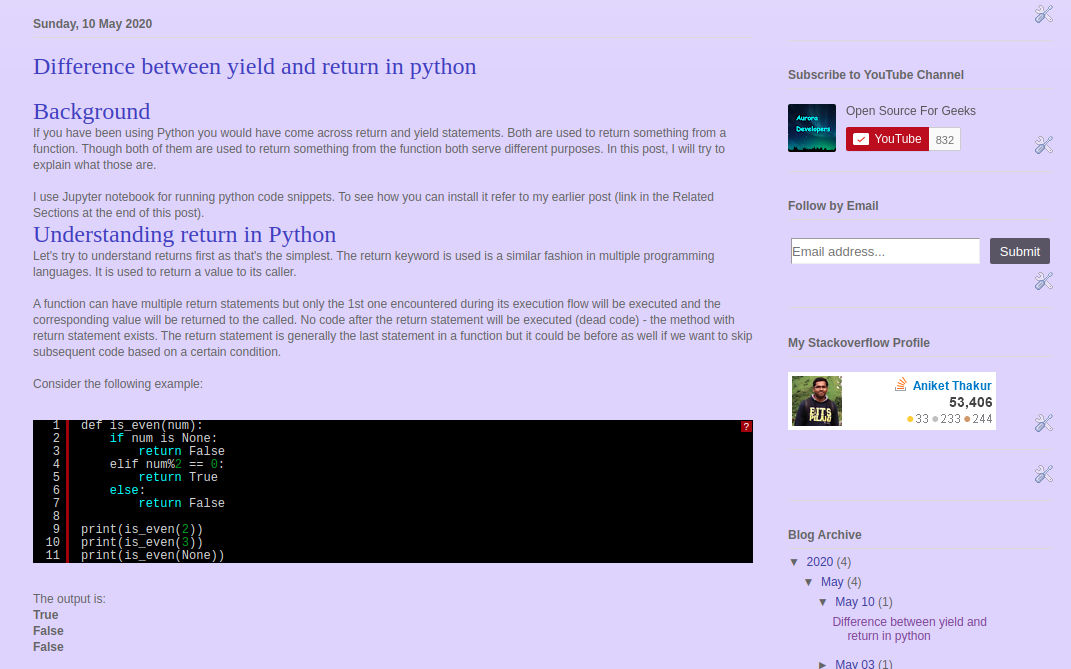
In this post, I will show you how you can achieve this.
How to add code Syntax highlighting to your blogger blog?
For code syntax highlighting we will use SyntaxHighlighter. I will specifically tell you how to add this to your blogger blog.- Open your blogger blog dashboard
- Go to Theme
- Click on 3 dots beside "My theme" and click on "Edit HTML"


- In the panel which opens and shows some HTML code search and go to the line with </head> tag. This is where your head tag ends. We need to add some include CSS and js files here along with some custom javascript.
- Inside the head tag (Just before </head> add following code)
<!-- Syntax Highlighter START --> <link href="http://alexgorbatchev.com/pub/sh/current/styles/shCore.css" rel="stylesheet" type="text/css"></link> <link href="http://alexgorbatchev.com/pub/sh/current/styles/shThemeDefault.css" rel="stylesheet" type="text/css"></link> <script src="http://alexgorbatchev.com/pub/sh/current/scripts/shCore.js" type="text/javascript"> <script src='http://alexgorbatchev.com/pub/sh/current/scripts/shBrushAS3.js' type='text/javascript'/> <script src='http://alexgorbatchev.com/pub/sh/current/scripts/shBrushBash.js' type='text/javascript'/> <script src='http://alexgorbatchev.com/pub/sh/current/scripts/shBrushColdFusion.js' type='text/javascript'/> <script src='http://alexgorbatchev.com/pub/sh/current/scripts/shBrushCSharp.js' type='text/javascript'/> <script src='http://alexgorbatchev.com/pub/sh/current/scripts/shBrushCpp.js' type='text/javascript'/> <script src='http://alexgorbatchev.com/pub/sh/current/scripts/shBrushCss.js' type='text/javascript'/> <script src='http://alexgorbatchev.com/pub/sh/current/scripts/shBrushDelphi.js' type='text/javascript'/> <script src='http://alexgorbatchev.com/pub/sh/current/scripts/shBrushDiff.js' type='text/javascript'/> <script src='http://alexgorbatchev.com/pub/sh/current/scripts/shBrushErlang.js' type='text/javascript'/> <script src='http://alexgorbatchev.com/pub/sh/current/scripts/shBrushGroovy.js' type='text/javascript'/> <script src='http://alexgorbatchev.com/pub/sh/current/scripts/shBrushJScript.js' type='text/javascript'/> <script src='http://alexgorbatchev.com/pub/sh/current/scripts/shBrushJava.js' type='text/javascript'/> <script src='http://alexgorbatchev.com/pub/sh/current/scripts/shBrushJavaFX.js' type='text/javascript'/> <script src='http://alexgorbatchev.com/pub/sh/current/scripts/shBrushPerl.js' type='text/javascript'/> <script src='http://alexgorbatchev.com/pub/sh/current/scripts/shBrushPhp.js' type='text/javascript'/> <script src='http://alexgorbatchev.com/pub/sh/current/scripts/shBrushPlain.js' type='text/javascript'/> <script src='http://alexgorbatchev.com/pub/sh/current/scripts/shBrushPowerShell.js' type='text/javascript'/> <script src='http://alexgorbatchev.com/pub/sh/current/scripts/shBrushPython.js' type='text/javascript'/> <script src='http://alexgorbatchev.com/pub/sh/current/scripts/shBrushRuby.js' type='text/javascript'/> <script src='http://alexgorbatchev.com/pub/sh/current/scripts/shBrushScala.js' type='text/javascript'/> <script src='http://alexgorbatchev.com/pub/sh/current/scripts/shBrushSql.js' type='text/javascript'/> <script src='http://alexgorbatchev.com/pub/sh/current/scripts/shBrushVb.js' type='text/javascript'/> <script src='http://alexgorbatchev.com/pub/sh/current/scripts/shBrushXml.js' type='text/javascript'/> <script language='javascript' type='text/javascript'> SyntaxHighlighter.config.bloggerMode = true; SyntaxHighlighter.all(); </script>
- Once done save the file and reload blog.

- Now if you want any highlighting you can use the corresponding class in <pre> tag. Eg for Java you can do
<pre class="brush:java">This will be highlighted</pre>
- Instead of Java you can have other languages as well. Choices are: cpp, c, c++, c#, c-sharp, csharp, css, delphi, pascal, java, js, jscript, javascript, php, py, python, rb, ruby, rails, ror, sql, vb, vb.net, xml, html, xhtml, xslt. You can see the latest list of supported languages.
- You can only add js files for brushes you need (See optimization below)
Optimizations
This is the good part! We would not call ourselves programmers if we did not have an optimization part :)- You can see above there are a bunch of js files added in the head tag. You might not need all and each page load with load these external JS code which can slow loading if your blog. So Add only those JS files which you need. In fact, if you see the screenshot above I have used just the Java brush JS. I just use the same for all types of codes.

- If you do not want the code highlighting to work for your homepage (Just for the the posts you write), you can add all above code inside the following tags:
<b:if cond='data:blog.pageType == "item"'> </b:if>
- Lastly, you would have also noticed the link base path for JS and CSS files are different in my code that what I originally provided. That's because I have used the CDN path(https://cdnjs.com/libraries/SyntaxHighlighter). This is done primarily for 2 things:
- First, it allows highlighting to work even on https. By default with the above code loading your blog site with https protocol will not show highlighting. That's because your include scripts are HTTP and not supported for https.
- Secondly, if the HTTP links are down you are screwed. CDN caches the scripts and cs files. So you can always rely on it (rely is is a strong word but it's better than those HTTP links :) )

Configuration
- Another thing you might have noticed is the change of theme file I have used. The original set of code I proposed uses a default theme shThemeDefault.css but I have changed this to use shThemeEmacs.css. You can use whichever theme you like - Just include the corresponding theme CSS file (and remove the default one). Some of the available themes are: shThemeRDark, shThemeMidnight, shThemeMDUltra, shThemeFadeToGrey, shThemeEmacs, shThemeEclipse, shThemeDjango, shThemeDefault, shCoreRDark, shCoreMidnight, shCoreMDUltra, shCoreFadeToGrey, shCoreEmacs, shCoreEclipse, shCoreDjango, shCoreDefault
- I already mentioned you should only include and use the JS files corresponding to language brushed you intent to use. This will reduce your page load time. You can also use the "b:if" tag I mentioned above so that these scripts load for your blog posts.
You can already see this blog using all of these customizations. Feel free to comment if you need any help. Thanks.