Background
Generally what happens in a https connections is that client asks for SSL certificate from the SSL compliant server it is communicating with over https. Server will provide a certificate from it's key store. After client receives this certificate it validates it's credentials depending on whether- hostname is same as requested
- has a verifiable chain of trust back to a trusted (root) certificate [from clients trust store]
Now if connections are proxied and you can get the device to trust your (rogue) root CA certificate then you can intercept the secure connections. This is essentially man-in-the-middle attack. Now here is what happens in SSL pinning which potentially adds an extra security layer from man-in-the-middle attacks-
App bundles the known server certificates with it. When app tries to make a secure connection with the server, it validates the certificate received by the server with the ones it has bundled with. So even if OS validates the received certificate chain against a (potentially rogue) root CA, the app will reject the connection displaying network error.
Common type of certificates
In summary, there are four different ways to present certificates and their components:
- PEM Governed by RFCs, it's used preferentially by open-source software. It can have a variety of extensions (.pem, .key, .cer, .cert, more)
- PKCS7 An open standard used by Java and supported by Windows. Does not contain private key material.
- PKCS12 A private standard that provides enhanced security versus the plain-text PEM format. This can contain private key material. It's used preferentially by Windows systems, and can be freely converted to PEM format through use of openssl.
- DER The parent format of PEM. It's useful to think of it as a binary version of the base64-encoded PEM file. Not routinely used by much outside of Windows.
PEM on it's own isn't a certificate, it's just a way of encoding data. X.509 certificates are one type of data that is commonly encoded using PEM.
PEM is a X.509 certificate (whose structure is defined using ASN.1), encoded using the ASN.1 DER (distinguished encoding rules), then run through Base64 encoding and stuck between plain-text anchor lines (BEGIN CERTIFICATE and END CERTIFICATE).
You can represent the same data using the PKCS#7 or PKCS#12 representations, and the openssl command line utility can be used to do this.
Convert a PEM-formatted String to a java.security.cert.X509Certificate
public static X509Certificate parseCertificate(String certStr) throws CertificateException{
//before decoding we need to get rod off the prefix and suffix
byte [] decoded = Base64.decode(certStr.replaceAll(X509Factory.BEGIN_CERT, "").replaceAll(X509Factory.END_CERT, ""));
return (X509Certificate)CertificateFactory.getInstance("X.509").generateCertificate(new ByteArrayInputStream(decoded));
}
How to get PEM certificate of the SSL/https compatible site
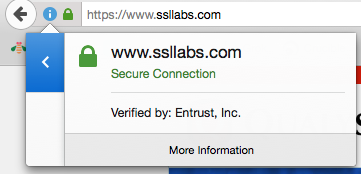
- Go to that particular website on your browser. Lets say we go to -
- https://www.ssllabs.com/
- Now look at the top left of the URL bar. You should see details of the connection. And certificate details if your connection is https -



- Next click on view certificate and click on Details -


- Now click on Export and save your file is PEM format -






You can find app for this ready in playstore -
Related Links
- What is a Pem file and how does it differ from other OpenSSL Generated Key File Formats?
- What is certificate pinning?
- Convert a PEM-formatted String to a java.security.cert.X509Certificate(SO)
- Intercepting Android network calls using Fiddler Web Proxy(OSFG)
- How to resolve “enter the password for credential storage” issue?(SO)
- Android Cert pinning demo App in Playstore
- Certificate and Public Key Pinning (OWASP)