
Background
Following are some common terminal operations supported by Stream -
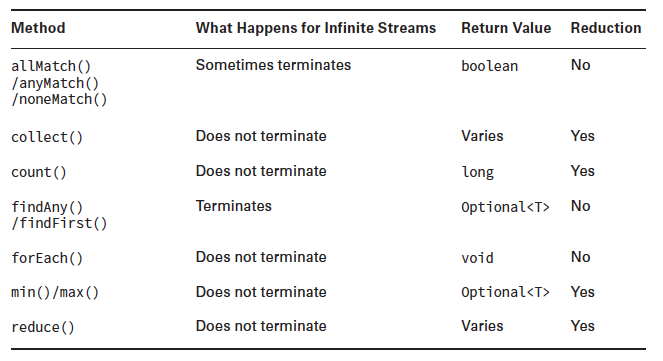
In this post we will see two of these - reduce() and collect(). As you can see they are reduction. They reduce stream to an object. Lets see each of them is detail now.
reduce()
reduce() method combines the stream into a single object. It can reduce the stream either to same same type as that of stream or different. Methods available for reduce are -
- T reduce(T identity, BinaryOperator<T> accumulator)
- Optional<T> reduce(BinaryOperator<T> accumulator)
- <U> U reduce(U identity, BiFunction<U,? super T,U> accumulator, BinaryOperator<U> combiner)
Let's see some examples -
Stream<String> myStringStream = Stream.of("a","n","i","k","e","t");
String stringResult = myStringStream.reduce("", (a,b) -> a + b);
System.out.println("String reduce : " + stringResult);
Stream<Integer> myIntegerStream = Stream.of(2,3,4,5,6);
int intResult = myIntegerStream.reduce(1, (a,b) -> a * b);
System.out.println("Intger reduce : " + intResult);
Output is -
String reduce : aniket
Intger reduce : 720
Intger reduce : 720
As you can see the 1st method gets the identity, then uses the 1st element of the stream and operates both to get a result. Then it takes the result and the 2nd element to process again and so on to finally return a result.
2nd method does not take an identity as an input well because it's not strictly mandatory but if you notice it returns an Optional value. There can be 3 cases here -
- If the stream is empty, an empty Optional is returned.
- If the stream has one element, it is returned.
- If the stream has multiple elements, the accumulator is applied to combine them.
For eg -
Stream<Integer> myIntegerStream = Stream.of(2,3,4,5,6);
Optional<Integer> intResult = myIntegerStream.reduce((a,b) -> a * b);
if(intResult.isPresent()) {
System.out.println("Intger reduce : " + intResult.get());
}
And the output is again -
Intger reduce : 720
3rd method is used mainly when parallel Streams are involved. In that case you stream is divided into segments, accumulator is used to combine individual segments and then a combiner is used to combine those segments.
For reduce arguments to be used for parallel streams it must satisfy following properties -
multiple elements in the stream, resulting in very unexpected data. So above properties should be obeyed.
For reduce arguments to be used for parallel streams it must satisfy following properties -
- The identity must be defined such that for all elements in the stream u ,
combiner.apply(identity, u) is equal to u . - The accumulator operator op must be associative and stateless such that (a op b) op c is equal to a op (b op c) .
- The combiner operator must also be associative and stateless and compatible with the identity, such that for all u and t combiner.apply(u,accumulator.apply(identity,t)) is equal to accumulator.apply(u,t) .
multiple elements in the stream, resulting in very unexpected data. So above properties should be obeyed.
collect()
collect() is again a reduction called mutable reduction. In this we use mutable objects like StringBuilder or ArrayList to collect data. Note the result here is different type than that of the stream content. Methods available are -
And the output is -
String reduce : aniket
String reduce : [a, e, i, k, n, t]
Or you can use the collectors -
Output -
[a, n, i, k, e, t]
For using collect() on parallel streams make sure your mutable container is thread safe. You can use concurrent collections for this.
- <R> R collect(Supplier<R> supplier, BiConsumer<R, ? super T> accumulator, BiConsumer<R, R> combiner)
- <R,A> R collect(Collector<? super T, A,R> collector)
Stream<String> myStringStream = Stream.of("a","n","i","k","e","t");
StringBuilder stringResult = myStringStream.collect(StringBuilder::new, StringBuilder::append,StringBuilder::append);
System.out.println("String reduce : " + stringResult.toString());
myStringStream = Stream.of("a","n","i","k","e","t");
TreeSet stringTreeSetResult = myStringStream.collect(TreeSet::new, TreeSet::add,TreeSet::addAll);
System.out.println("String reduce : " + stringTreeSetResult);
And the output is -
String reduce : aniket
String reduce : [a, e, i, k, n, t]
Or you can use the collectors -
Stream<String> myStringStream = Stream.of("a","n","i","k","e","t");
List<String> resultList = myStringStream.collect(Collectors.toList());
System.out.println(resultList);
Output -
[a, n, i, k, e, t]
For using collect() on parallel streams make sure your mutable container is thread safe. You can use concurrent collections for this.
Joining Collector
Simple joining collector will join elements with the specified delimiter -
public static void main(String[] args) {
List<String> myList = Arrays.asList("I","am","groot");
String result = myList.stream().collect(Collectors.joining(" "));
System.out.println("Collect using joining : " + result);
}
Output :
Collect using joining : I am groot
Collecting into Map
You can also collect your stream results into Map. Lets see how -
public static void main(String[] args) {
List<String> myList = Arrays.asList("I","am","groot");
Map<Integer,String> result = myList.stream().collect(Collectors.toMap(x -> x.length(),x -> x));
System.out.println("Collect using toMap : " + result);
Output :
Collect using toMap : {1=I, 2=am, 5=groot}
Here we are creating a map with key as length of the element in the stream and value as the element itself.
But wait what happens when I give input as - Arrays.asList("I","am","groot","ok") . There are two elements that will map to same key since both "am" and "ok" have same length. Well java does not know what to do and will just throw an Exception -
Exception in thread "main" java.lang.IllegalStateException: Duplicate key am
at java.util.stream.Collectors.lambda$throwingMerger$0(Collectors.java:133)
at java.util.HashMap.merge(HashMap.java:1245)
at java.util.stream.Collectors.lambda$throwingMerger$0(Collectors.java:133)
at java.util.HashMap.merge(HashMap.java:1245)
You can always tell Java how to handle this scenario as follows -
public static void main(String[] args) {
List<String> myList = Arrays.asList("I","am","groot","ok");
Map<Integer,String> result = myList.stream().collect(Collectors.toMap(x -> x.length(),x -> x, (a,b) -> a+ " " + b));
System.out.println("Collect using toMap : " + result);
}
Output :
Collect using toMap : {1=I, 2=am ok, 5=groot}
This is because we have given (a,b) -> a+ " " + b which bean if there are two elements mapping to same key concatenate them using a space and out it in the for the corresponding key.
Collect using grouping
You can collect using grouping to which will collect your data in the map based on your condition. Eg. -
public static void main(String[] args) {
List<String> myList = Arrays.asList("I","am","groot","ok");
Map<Integer,List<String>> result = myList.stream().collect(Collectors.groupingBy(String::length));
System.out.println("Collect using toMap : " + result);
}
Output :
Collect using toMap : {1=[I], 2=[am, ok], 5=[groot]}
Collect using Partitioning
Partitioning is a special type of grouping in which map just has two entries (for keys) and those are true and false. You need to give a predicate for the method to put stream element in correct bucket. Eg -
public static void main(String[] args) {
List<String> myList = Arrays.asList("I","am","groot","ok");
Map<Boolean,List<String>> result = myList.stream().collect(Collectors.partitioningBy(s -> s.length() > 3));
System.out.println("Collect using toMap : " + result);
}
Output :
Collect using toMap : {false=[I, am, ok], true=[groot]}
Difference between reduce() and collect()
- If you have immutable values such as ints,doubles,Strings then normal reduction works just fine. However, if you have to reduce your values into say a List (mutable data structure) then you need to use mutable reduction with the collect method.
- In the case of reduce() we apply the function to the stream elements themselves where as in the case of collect() we apply the function to a mutable container.

No comments:
Post a Comment